
彻底解决VB.NET获取网页源代码的乱码问题
作者:admin 日期:2022-10-28

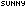

Function GetWebCode(ByVal strURL As String) As String
Dim httpReq As System.Net.HttpWebRequest
Dim httpResp As System.Net.HttpWebResponse
Dim httpURL As New System.Uri(strURL)
Dim ioS As System.IO.Stream, charSet As String, tCode As String
Dim k() As Byte
ReDim k(0)
Dim dataQue As New Queue(Of Byte)
httpReq = CType(WebRequest.Create(httpURL), HttpWebRequest)
Dim sTime As Date = CDate("1990-09-21 00:00:00")
httpReq.IfModifiedSince = sTime
httpReq.Method = "GET"
httpReq.Timeout = 7000
Try
httpResp = CType(httpReq.GetResponse(), HttpWebResponse)
Catch
Debug.Print("weberror")
GetWebCode = "<title>no thing found</title>" : Exit Function
End Try
'以上为网络数据获取
ioS = CType(httpResp.GetResponseStream, Stream)
Do While ioS.CanRead = True
Try
dataQue.Enqueue(ioS.ReadByte)
Catch
Debug.Print("read error")
Exit Do
End Try
Loop
ReDim k(dataQue.Count - 1)
For j As Integer = 0 To dataQue.Count - 1
k(j) = dataQue.Dequeue
Next
'以上,为获取流中的的二进制数据
tCode = Encoding.GetEncoding("UTF-8").GetString(k) '获取特定编码下的情况,毕竟UTF-8支持英文正常的显示
charSet = Replace(GetByDiv2(tCode, "charset=", """"), """", "") '进行编码类型识别
'以上,获取编码类型
If charSet = "" Then 'defalt
If httpResp.CharacterSet = "" Then
tCode = Encoding.GetEncoding("UTF-8").GetString(k)
Else
tCode = Encoding.GetEncoding(httpResp.CharacterSet).GetString(k)
End If
Else
tCode = Encoding.GetEncoding(charSet).GetString(k)
End If
Debug.Print(charSet)
'Stop
'以上,按照获得的编码类型进行数据转换
'将得到的内容进行最后处理,比如判断是不是有出现字符串为空的情况
GetWebCode = tCode
If tCode = "" Then GetWebCode = "<title>no thing found</title>"
End Function
将如上代码复制,并引用:
Imports System.Net
Imports System.IO
Imports System.Text.Encoding
Imports System.Text
然后,就可以使用这个代码完成网页源代码下载的工作了。
 上一篇: cefsharp 禁止图片加载
上一篇: cefsharp 禁止图片加载 下一篇: VB.net线程传递参数四种方法
下一篇: VB.net线程传递参数四种方法 文章来自: 本站原创
文章来自: 本站原创 Tags: vb.net
Tags: vb.net  相关日志:
相关日志:
广告位






