
VB.net读取不同编码文本 解决乱码问题
作者:admin 日期:2022-08-25

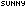

Public Function ReadAsString(ByVal buff() As Byte) As String
Dim stream As Stream = New MemoryStream(buff)
Dim position As Int64 = 0
Try
stream.Position = position
Dim reader As New StreamReader(stream, New UTF8Encoding(False, True), True)
Return reader.ReadToEnd
Catch exception As DecoderFallbackException
stream.Position = position
Dim reader2 As New StreamReader(stream, Encoding.Default) '.GetEncoding(&H4E4))
'Debug.Print(reader2.CurrentEncoding.ToString)
Return reader2.ReadToEnd
Catch ex As Exception
Debug.Print(ex.Message & vbCrLf & ex.StackTrace)
End Try
Return ""
End Function
c#和asp.net的版本参见下面的链接:
http://stackoverflow.com/questions/90838/how-can-i-detect-the-encoding-codepage-of-a-text-file/5830273#5830273
上述代码为VB.NET函数,C#和ASP.NET版,参见上面注释里的链接。
C#、VB.NET、ASP.NET 通用解决获取网页源码乱码问题原因,中文文本乱码完美方案。
这里强调一下,网络上所谓的使用请求头、Html中的编码都不能完美解决乱码问题,上述代码方案,只管读取结果,不管什么头、什么Html指定,都是扯淡。没用的,这个方案读取任意txt文件可以保证不再乱码,txt指任意文本内容,不是指txt后缀文件。
参数为二进制数组,二进制数组哪里来?看下面
1. io.file.readallbytes(file)
2. webclient.downdata(url)
3. System.Net.HttpWebResponse .GetResponseStream 获取字节数组。
以上99.99%解决编码问题,当然非要说还是乱码的也还是会有,那就是你给你二进制保存到txt用记事本打开本身就会乱码,但极端情况还是手动人工指定一下因定编码解析吧。以上用于自动分析编码使用。
如果只是要自动获取编码的类型,可以在上述两处打印:
Select Case reader2.CurrentEncoding.CodePage
Case 1200
ReturnEncodeMode = "Unicode"
Case 1201
ReturnEncodeMode = "BigUnicode"
Case 936
ReturnEncodeMode = "ANSI"
Case 65001
ReturnEncodeMode = "UTF8"
End Select
 上一篇:
上一篇:  下一篇:
下一篇:  文章来自:
文章来自:  Tags:
Tags:  相关日志:
相关日志:
评论: 0 | 引用: 0 | 查看次数: 194
发表评论
广告位






